이번 포스트에서는 파이썬에서 자주 사용되는 BeautifulSoup을 이용한 크롤링을 해보려 한다.
1. 크롤링(Crawling)
무수히 많은 컴퓨터에 분산 저장되어 있는 문서를 수집하여 검색 대상의 색인으로 포함시키는 기술.
웹 스크래핑과 함께 많이 사용되는 단어인데, 스크래핑과의 차이점이라면
웹 크롤링은 뚜렷한 목표가 없이 웹사이트를 지정하면 특정 횟수만큼 사이트의 정보를 수집하는 것이 아니라 해당 사이트를 지속적으로 탐색하며 수많은 데이터들을 가져온다.
https://nadocoding.tistory.com/10
[나도코딩] 파이썬 활용편3 웹스크래핑 - 소개
혹시 늑대와 일곱 마리 아기 염소 이야기, 기억 하시나요? 엄마가 집을 비운 사이 일곱 마리 아기 염소만 남아 있는데 나쁜 늑대가 찾아옵니다. "나 엄마야, 문 좀 열어줘" 근데
nadocoding.tistory.com
스크래핑과 웹 크롤링의 차이점은 해당 블로그에 잘 소개되어 있다.
2. BeautifulSoup
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object (unicode() in Python 2), or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str(
www.crummy.com
Beautifulsoup는 HTML과 XML파일로부터 데이터를 뽑아내기 위한 파이썬 라이브러리이다.
주로 크롤링 라이브러리로는 Selenium과 BeautifulSoup를 많이 사용한다.
Selenium은 크롬 드라이버를 이용하여 웹 브라우저를 실행시키고 그 브라우저를 통하여 데이터를 받아오며, 해당 웹사이트가 동적으로 구성되어 있을때 데이터 추출이 어려운데, 이 상황에서도 데이터 추출을 가능하게 해준다.
Beautifulsoup은 HTML 태그정보를 이용하여 데이터를 가져오기 떄문에 Selenium보다는 빠른 속도로 데이터를 가져올 수 있다.
크롤링 해보기 - 네이버 경제 메인
1. Beautifulsoup 설치
pip install bs4
pip install beautifulsoup4둘 중 어떤 명령어를 사용하더라도 똑같은 모듈을 다운로드할 수 있다.
2. HTML 구조 살펴보기
https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101
경제 : 네이버 뉴스
증권, 금융, 부동산, 기업, 국제 등 경제 분야 뉴스 제공
news.naver.com
살펴볼 페이지는 네이버 뉴스 - 경제 헤드라인 페이지를 살펴볼 것이다
해당 페이지에서 F12 버튼을 눌러주면

이런 구조를 가진 페이지를 확인할 수 있다.
여기서 크롤링할 정보는 뉴스 제목, 기사내용, 작성 언론사, 이미지 정보까지 크롤링 해보도록 한다.

해당하는 부분이 cluster 클래스 내부에 cluster_group의 형태로 묶여 반복되고 있는 모습을 볼 수 있다.
여기서 조금 더 들어가보면
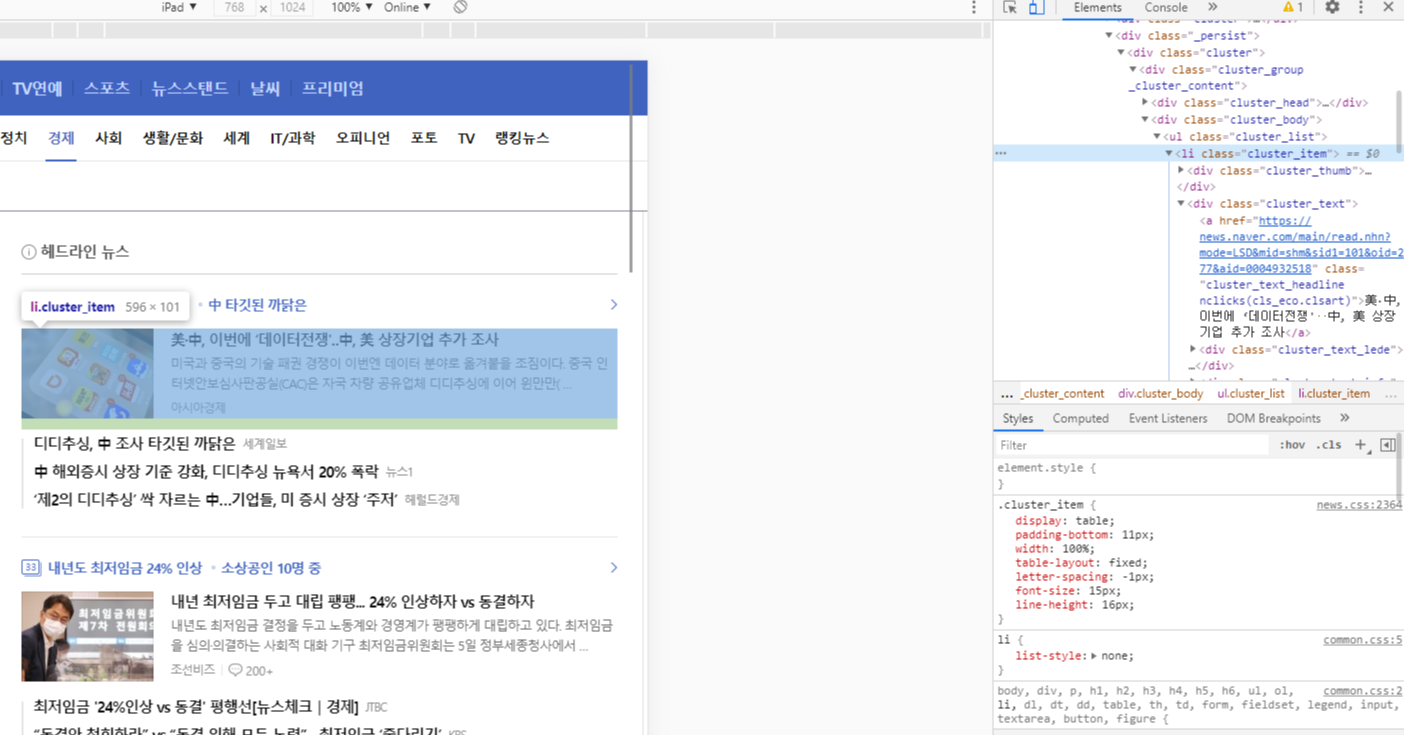
해당 li태그 내부에 정보들이 들어있는 모습을 확인할 수 있다.

그럼 해당 태그 내부의 제목, 기사내용, 언론사 부분에 copy - copy selector를 이용하여 복사해준다.
3. 코드 작성
# import는 상단에
import requests
from bs4 import BeautifulSoup
#네이버 경제 메인
url = f'https://news.naver.com/main/main.nhn?mode=LSD&mid=shm&sid1=101'
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"}
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,'html.parser')
my_news = soup.select('#main_content > div > div._persist > div:nth-child(1) > div.cluster_group._cluster_content > div.cluster_body > ul > li:nth-child(1) > div.cluster_text > a')
my_news_content = soup.select('#main_content > div > div._persist > div:nth-child(1) > div.cluster_group._cluster_content > div.cluster_body > ul > li:nth-child(1) > div.cluster_text > div.cluster_text_lede')
my_news_writing = soup.select('#main_content > div > div._persist > div:nth-child(1) > div.cluster_group._cluster_content > div.cluster_body > ul > li:nth-child(1) > div.cluster_text > div.cluster_text_info > div')
my_news_image = soup.select('#main_content > div > div._persist > div:nth-child(1) > div.cluster_group._cluster_content > div.cluster_body > ul > li:nth-child(1) > div.cluster_thumb > div.cluster_thumb_inner > a > img')
newslist = list()
nnews = list()
for news in my_news: # 뉴스 제목을 리스트에 append
nnews.append(news.text.strip())
for i in range(len(nnews)):
title = my_news[i].text.strip()
link = my_news[i].get('href')
content = my_news_content[i].text.strip()
writing = my_news_writing[i].text.strip()
try: #list index out of range 방지를 위한 예외처리
image_s = my_news_image[i].get('src')
image = my_news_image[i].get('src').replace('nf132_90','w647') # 크기 조정을 위한 replace
except:
image_s="NO IMAGE"
image = "NO IMAGE"
item_obj = {
'title': title,
'link': link,
'content': content,
'writing': writing,
'image': image,
'image_s': image_s,
}
newslist.append(item_obj)
print(newslist)
코드는 다음과 같이 작성하였다.
해당 링크에서 뉴스 제목을 가져오고, 뉴스 기사의 수 만큼 반복하여 제목, 링크, 내용, 언론사, 이미지정보를 가져온다.
해당 image를 크롤링하면서 image_s와 image로 나눈 이유는 django 웹에서 표시할 때 이미지 크기를 조절해주기 위해 코드에서 바꿔주었다.
코드를 실행시켜 보면

다음과 같이 리스트에 잘 표시되는 것을 확인할 수 있다.
이것을 다시 Django 웹에서 표시해 보면

크롤링한 해당 정보들을 잘 가져오는 것을 확인할 수 있다.
Django HTML 코드
<!-- django의 HTML 코드 -->
<ul>
<!-- edit. 리스트 두개를 한번에 받아서 출력 -->
{%for home in data %}
<tr>
<td>
<div class="row">
<div class="col-3 p-3"><a href="{{home.link}}"><img src="{{home.image_s}}"></img></a></div>
<div class="col-9 p-3" style="font-size:14px;">
<div class="text-secondary" style="font-size:12px;">{{home.writing}} · 경제 메인</div>
<a href="{{ home.link }}"><b>{{home.title}}</b></a><br>
<div class="mt-2" style="font-size: 12px">{{home.content}}</div>
</div>
</div>
</td>
</tr>
{%endfor%}
<!-- -->
</ul>
'Python > 여러가지' 카테고리의 다른 글
| [Python/기본] 파이썬 Anaconda(아나콘다) 가상환경 설치하기(+32비트) (0) | 2021.06.29 |
|---|---|
| [Python/기본] 파이썬 가상 개발환경 설정하기 (0) | 2021.06.28 |